DNA: Geschichte, Funktionen, Struktur, Komponenten
DNA (Desoxyribonukleinsäure) ist das Biomolekül, das alle Informationen enthält, die zur Erzeugung eines Organismus und zur Aufrechterhaltung seiner Funktionsfähigkeit erforderlich sind. Es besteht aus Einheiten, die als Nukleotide bezeichnet werden und aus einer Phosphatgruppe, einem Zuckermolekül mit fünf Kohlenstoffatomen und einer stickstoffhaltigen Base bestehen.
Es gibt vier stickstoffhaltige Basen: Adenin (A), Cytosin (C), Guanin (G) und Thymin (T). Adenin paart sich immer mit Thymin und Guanin mit Cytosin. Die im DNA-Strang enthaltene Botschaft wird in eine Messenger-RNA umgewandelt, die an der Proteinsynthese beteiligt ist.

DNA ist ein extrem stabiles Molekül, das bei physiologischem pH-Wert negativ geladen ist und mit positiven Proteinen (Histonen) assoziiert ist, um sich im Kern eukaryotischer Zellen effizient zu verdichten. Eine lange Kette von DNA bildet zusammen mit verschiedenen assoziierten Proteinen ein Chromosom.
Geschichte
Im Jahr 1953 gelang es dem Amerikaner James Watson und dem Briten Francis Crick, die dreidimensionale Struktur der DNA dank der kristallographischen Arbeit von Rosalind Franklin und Maurice Wilkins aufzuklären. Sie stützten ihre Schlussfolgerungen auch auf die Werke anderer Autoren.
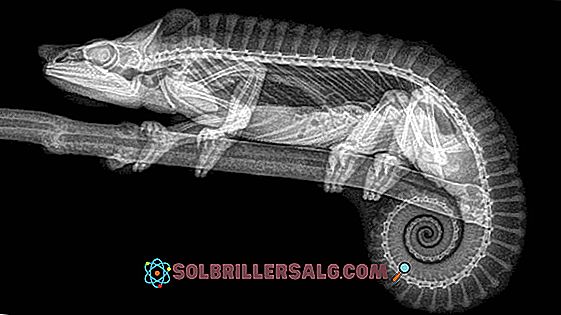
Wenn die DNA Röntgenstrahlen ausgesetzt wird, entsteht ein Beugungsmuster, anhand dessen auf die Struktur des Moleküls geschlossen werden kann: eine Helix aus zwei antiparallelen Ketten, die sich nach rechts drehen, wobei beide Ketten durch Wasserstoffbrückenbindungen zwischen den Basen verbunden sind . Das erhaltene Muster war wie folgt:

Die Struktur kann nach den Gesetzen der Bragg-Beugung angenommen werden: Wenn ein Objekt in der Mitte eines Röntgenstrahls angeordnet ist, wird es reflektiert, da die Elektronen des Objekts mit dem Strahl interagieren.
Am 25. April 1953 wurden die Ergebnisse von Watson und Crick in der renommierten Fachzeitschrift Nature in einem zweiseitigen Artikel mit dem Titel " Molekulare Struktur von Nukleinsäuren " veröffentlicht, der das Gebiet der Biologie völlig revolutionieren würde.
Dank dieser Entdeckung erhielten die Forscher 1962 den Nobelpreis für Medizin, mit Ausnahme von Franklin, der vor der Entbindung starb. Gegenwärtig ist diese Entdeckung einer der großen Vertreter des Erfolgs der wissenschaftlichen Methode, neues Wissen zu erwerben.
Komponenten
Das DNA-Molekül besteht aus Nukleotiden, Einheiten, die aus einem Zucker mit fünf Kohlenstoffen, der an eine Phosphatgruppe gebunden ist, und einer stickstoffhaltigen Base gebildet werden. Der in der DNA gefundene Zuckertyp ist vom Desoxyribosetyp und daher der Name Desoxyribonukleinsäure.
Zur Bildung der Kette werden die Nukleotide mittels einer 3'-Hydroxylgruppe (-OH) von einem Zucker und dem 5'-Phosphafo vom nächsten Nukleotid durch eine Phosphodiesterbindung kovalent verbunden.
Verwechseln Sie Nukleotide nicht mit Nukleosiden. Letzteres bezieht sich auf den Teil des Nucleotids, der nur aus der Pentose (Zucker) und der stickstoffhaltigen Base besteht.
Die DNA besteht aus vier Arten stickstoffhaltiger Basen: Adenin (A), Cytosin (C), Guanin (G) und Thymin (T).
Die stickstoffhaltigen Basen werden in zwei Kategorien eingeteilt: Purine und Pyrimidine. Die erste Gruppe besteht aus einem Ring mit fünf Atomen, der mit einem weiteren Ring mit sechs Atomen verbunden ist, während die Pyrimidine aus einem einzigen Ring bestehen.
Von den genannten Basen sind Adenin und Guanin Derivate von Purinen. Im Gegensatz dazu gehört die Gruppe der Pyrimidine zu Thymin, Cytosin und Uracil (im RNA-Molekül vorhanden).
Struktur

Ein DNA-Molekül besteht aus zwei Nukleotidketten. Diese "Kette" ist als DNA-Strang bekannt.
Die beiden Stränge sind durch Wasserstoffbrückenbindungen zwischen den komplementären Basen verbunden. Die stickstoffhaltigen Basen sind kovalent an ein Gerüst aus Zuckern und Phosphaten gebunden.
Jedes in einem Strang befindliche Nukleotid kann mit einem anderen spezifischen Nukleotid des anderen Strangs gekoppelt werden, um die bekannte Doppelhelix zu bilden. Um eine effiziente Struktur zu bilden, koppelt A immer über zwei Wasserstoffbrücken mit T und G über drei Brücken mit C.
Chargaffs Gesetz
Wenn wir die Anteile stickstoffhaltiger Basen in der DNA untersuchen, werden wir feststellen, dass die Menge von A mit der Menge von T identisch ist und mit G und C. Dieses Muster ist als Chargaffsches Gesetz bekannt.
Diese Paarung ist energetisch günstig, da eine ähnliche Breite entlang der Struktur und ein ähnlicher Abstand entlang des Moleküls des Zucker-Phosphat-Gerüsts beibehalten werden kann. Es ist zu beachten, dass eine Basis eines Rings mit einer Basis eines Rings gekoppelt ist.
Modell der Doppelhelix
Es wird vorgeschlagen, dass die Doppelhelix aus 10, 4 Nucleotiden pro Windung besteht, die durch einen Abstand von Mitte zu Mitte von 3, 4 Nanometern voneinander getrennt sind. Der Wickelvorgang führt zur Bildung von Rillen in der Struktur, wobei eine Haupt- und eine Nebenrille beobachtet werden können.
Die Rillen entstehen, weil sich die glykosidischen Bindungen in den Basenpaaren hinsichtlich ihres Durchmessers nicht gegenüberstehen. In der kleinen Furche befindet sich das Pyrimidin O-2 und das Purin N-3, während sich die große Furche in der gegenüberliegenden Region befindet.
Wenden wir die Analogie einer Leiter an, so bestehen die Sprossen aus den zueinander komplementären Basispaaren, während das Skelett den beiden Griffschienen entspricht.
Die Enden des DNA-Moleküls sind nicht gleich, daher spricht man von einer "Polarität". Eines seiner Enden, 3 ', trägt eine Gruppe -OH, während das 5'-Ende die freie Phosphatgruppe aufweist.
Die beiden Stränge sind antiparallel angeordnet, was bedeutet, dass sie wie folgt entgegengesetzt zu ihren Polaritäten angeordnet sind:
Außerdem muss die Sequenz eines der Stränge zu seinem Partner komplementär sein. Wenn es sich um eine Position A handelt, muss der antiparallele Strang ein T sein.
Organisation
In jeder menschlichen Zelle befinden sich ungefähr zwei Meter DNA, die effizient verpackt werden müssen.
Der Strang muss verdichtet werden, damit er in einem mikroskopisch kleinen Kern von 6 μm Durchmesser enthalten sein kann, der nur 10% des Zellvolumens einnimmt. Dies ist dank der folgenden Verdichtungsstufen möglich:
Histone
In Eukaryoten gibt es Proteine, sogenannte Histone, die die Fähigkeit besitzen, sich an das DNA-Molekül zu binden, das die erste Stufe der Verdichtung des Strangs darstellt. Die Histone haben positive Ladungen, um mit den negativen Ladungen der DNA, die von den Phosphaten eingebracht werden, in Wechselwirkung treten zu können.
Histone sind solche wichtigen Proteine für eukaryotische Organismen, die im Verlauf der Evolution praktisch unverändert geblieben sind. Dabei ist zu berücksichtigen, dass eine geringe Mutationsrate darauf hinweist, dass der selektive Druck auf das Molekül stark ist. Ein Defekt der Histone könnte zu einer fehlerhaften Verdichtung der DNA führen.
Die Histone können biochemisch modifiziert werden und dieser Prozess verändert den Grad der Verdichtung des genetischen Materials.
Wenn die Histone "hypoacetyliert" sind, ist das Chromatin stärker kondensiert, da die acetylierten Formen die positiven Ladungen der Lysine (positiv geladene Aminosäuren) im Protein neutralisieren.
Nukleosomen und 30 nm Faser
Der DNA-Strang ist in den Histonen aufgerollt und bildet Strukturen, die den Perlen einer Perlenkette, den Nukleosomen, ähneln. Das Herzstück dieser Struktur sind zwei Kopien jeder Art von Histonen: H2A, H2B, H3 und H4. Die Vereinigung der verschiedenen Histone wird als "Histonoctamer" bezeichnet.
Das Oktamer ist von 146 Basenpaaren umgeben, die weniger als zwei Windungen ergeben. Eine humane diploide Zelle enthält ungefähr 6, 4 × 10 9 Nukleotide, die in 30 Millionen Nukleosomen organisiert sind.
Die Organisation in Nukleosomen ermöglicht es, die DNA in mehr als einem Drittel ihrer ursprünglichen Länge zu verdichten.
Bei einem Prozess der Extraktion des genetischen Materials unter physiologischen Bedingungen wird beobachtet, dass die Nukleosomen in einer Faser von 30 Nanometern angeordnet sind.
Chromosomen
Chromosomen sind die funktionale Vererbungseinheit, deren Funktion es ist, die Gene eines Individuums zu tragen. Ein Gen ist ein DNA-Abschnitt, der die Informationen zur Synthese eines Proteins (oder einer Reihe von Proteinen) enthält. Es gibt jedoch auch Gene, die für regulatorische Elemente wie RNA kodieren.
Alle menschlichen Zellen (außer Gameten und Bluterythrozyten) haben zwei Kopien jedes Chromosoms, eine vom Vater und die andere von der Mutter geerbt.
Chromosomen sind Strukturen, die aus einem langen linearen Teil der DNA zusammengesetzt sind, die mit den oben erwähnten Proteinkomplexen assoziiert sind. Normalerweise ist bei Eukaryoten das gesamte im Kern enthaltene genetische Material in eine Reihe von Chromosomen unterteilt.

Organisation in Prokaryoten
Prokaryoten sind Organismen, denen ein Kern fehlt. Bei diesen Spezies ist das genetische Material zusammen mit alkalischen Proteinen mit niedrigem Molekulargewicht stark gewickelt. Auf diese Weise wird die DNA verdichtet und befindet sich in einem zentralen Bereich des Bakteriums.
Einige Autoren bezeichnen diese Struktur gewöhnlich als "bakterielles Chromosom", obwohl sie nicht die gleichen Eigenschaften wie ein eukaryotisches Chromosom aufweist.
DNA-Menge
Nicht alle Arten von Organismen enthalten die gleiche Menge an DNA. Tatsächlich ist dieser Wert zwischen den Arten sehr unterschiedlich, und es besteht kein Zusammenhang zwischen der DNA-Menge und der Komplexität des Organismus. Dieser Widerspruch wird als "Paradoxon des Wertes C" bezeichnet.
Die logische Begründung wäre zu verstehen, dass der Organismus umso mehr DNA besitzt, je komplexer er ist. Dies ist jedoch in der Natur nicht wahr.
Zum Beispiel hat das Genom des Lungenfisches Protopterus aethiopicus eine Größe von 132 pg (DNA kann in Pikogramm = pg quantifiziert werden), während das menschliche Genom nur 3, 5 pg wiegt.
Denken Sie daran, dass nicht die gesamte DNA eines Organismus für Proteine kodiert, ein großer Teil davon hängt mit regulatorischen Elementen und verschiedenen Arten von RNA zusammen.
Strukturformen der DNA
Das aus Röntgenbeugungsmustern abgeleitete Watson- und Crick-Modell ist als B-DNA-Helix bekannt und das "traditionelle" und bekannteste Modell. Es gibt jedoch zwei andere Formen, die als DNA-A und DNA-Z bezeichnet werden.
DNA-A

Variante "A" dreht sich wie DNA-B nach rechts, ist jedoch kürzer und breiter. Diese Form tritt auf, wenn die relative Luftfeuchtigkeit abnimmt.
Die DNA-A rotiert alle 11 Basenpaare, die Hauptfurche ist schmaler und tiefer als die B-DNA. In Bezug auf die Moll-Rille ist dies oberflächlicher und breiter.
ADN-Z
Die dritte Variante ist die Z-DNA. Es ist die engste Form, die von einer Gruppe von Hexanukleotiden gebildet wird, die in einem Doppelstrang von antiparallelen Ketten organisiert sind. Eines der auffälligsten Merkmale dieser Form ist, dass sie sich nach links dreht, während die beiden anderen Formen dies nach rechts tun.
Z-DNA erscheint, wenn es kurze Sequenzen von alternierenden Pyrimidinen und Purinen gibt. Die größere Furche ist flach und die kleinere schmaler und tiefer als die B-DNA.
Obwohl das DNA-Molekül unter physiologischen Bedingungen meist in seiner B-Form vorliegt, zeigt die Existenz der beiden beschriebenen Varianten die Flexibilität und Dynamik des genetischen Materials.
Funktionen
Das DNA-Molekül enthält alle Informationen und Anweisungen, die zum Aufbau eines Organismus erforderlich sind. Die gesamte genetische Information in Organismen wird als Genom bezeichnet .
Die Nachricht wird durch das "biologische Alphabet" codiert: die vier zuvor erwähnten Basen A, T, G und C.
Die Nachricht kann zur Bildung verschiedener Arten von Proteinen oder zur Kodierung eines regulatorischen Elements führen. Der Vorgang, mit dem diese Basen eine Nachricht übermitteln können, wird nachfolgend erläutert:
Replikation, Transkription und Übersetzung
Die Nachricht, die in den vier Buchstaben A, T, G und C verschlüsselt ist, ergibt als Ergebnis einen Phänotyp (nicht alle DNA-Sequenzen kodieren für Proteine). Um dies zu erreichen, muss sich die DNA in jedem Prozess der Zellteilung selbst replizieren.
Die DNA-Replikation ist semikonservativ: Ein Strang dient als Vorlage für die Bildung des neuen Tochtermoleküls. Verschiedene Enzyme katalysieren die Replikation, einschließlich DNA-Primase, DNA-Helicase, DNA-Ligase und Topoisomerase.
Anschließend muss die in einer Basensequenzsprache geschriebene Nachricht an ein Zwischenmolekül übertragen werden: RNA (Ribonukleinsäure). Dieser Vorgang wird als Transkription bezeichnet.
Damit die Transkription stattfinden kann, müssen verschiedene Enzyme beteiligt sein, einschließlich der RNA-Polymerase.
Dieses Enzym ist dafür verantwortlich, die DNA-Nachricht zu kopieren und in ein Boten-RNA-Molekül umzuwandeln. Mit anderen Worten, der Zweck der Transkription besteht darin, den Boten zu erhalten.
Schließlich wird die Botschaft dank der Ribosomen in Boten-RNA-Moleküle übersetzt.
Diese Strukturen nehmen die Boten-RNA auf und bilden zusammen mit der Translationsmaschinerie das angegebene Protein.
Der genetische Code
Die Nachricht wird in "Drillingen" oder Gruppen von drei Buchstaben gelesen, die für eine Aminosäure - die Strukturblöcke der Proteine - spezifizieren. Es ist möglich, die Botschaft der Drillinge zu entschlüsseln, da der genetische Code bereits vollständig enthüllt wurde.
Die Translation beginnt immer mit der Aminosäure Methionin, die vom Starttriplett: AUG kodiert wird. Das "U" stellt die Uracilbase dar und ist charakteristisch für RNA und ersetzt Thymin.
Wenn die Messenger-RNA beispielsweise die folgende Sequenz aufweist: AUG CCU CUU UUU UUA, wird sie in die folgenden Aminosäuren übersetzt: Methionin, Prolin, Leucin, Phenylalanin und Phenylalanin. Es ist zu beachten, dass zwei Tripletts - in diesem Fall UUU und UUA - für dieselbe Aminosäure kodieren: Phenylalanin.
Für diese Eigenschaft wird gesagt, dass der genetische Code entartet ist, da eine Aminosäure von mehr als einer Sequenz von Tripletts kodiert wird, mit Ausnahme der Aminosäure Methionin, die den Beginn der Translation bestimmt.
Der Prozess wird mit bestimmten Beendigungs- oder Stop-Triplets gestoppt: UAA, UAG und UGA. Sie sind unter den Bezeichnungen Ocker, Bernstein und Opal bekannt. Wenn das Ribosom sie erkennt, können sie der Kette keine Aminosäuren mehr hinzufügen.
Chemische und physikalische Eigenschaften
Nukleinsäuren sind von Natur aus sauer und wasserlöslich (hydrophil). Die Bildung von Wasserstoffbrücken zwischen den Phosphatgruppen und den Hydroxylgruppen von Pentosen mit Wasser kann auftreten. Es ist bei physiologischem pH-Wert negativ geladen.
Die DNA-Lösungen sind aufgrund der Widerstandsfähigkeit gegen die Verformung der Doppelhelix, die sehr starr ist, hochviskos. Die Viskosität nimmt ab, wenn die Nukleinsäure einzelsträngig ist.
Sie sind hochstabile Moleküle. Logischerweise muss dieses Merkmal in den Strukturen, die die genetische Information tragen, unverzichtbar sein. Im Vergleich zu RNA ist DNA viel stabiler, da es keine Hydroxylgruppe gibt.
Die DNA kann durch Hitze denaturiert werden, dh die Stränge werden getrennt, wenn das Molekül hohen Temperaturen ausgesetzt wird.
Die Wärmemenge, die angewendet werden muss, hängt vom G-C-Prozentsatz des Moleküls ab, da diese Basen durch drei Wasserstoffbrücken verbunden sind, was die Beständigkeit gegen Trennung erhöht.
Die Absorption von Licht hat einen Peak bei 260 Nanometern, der sich erhöht, wenn die Nukleinsäure einzelsträngig ist, da sie die Nukleotidringe freilegt und diese für die Absorption verantwortlich sind.
Evolution
Nach Lazcano et al. 1988 DNA entsteht in Phasen des Übergangs von RNA und ist eines der wichtigsten Ereignisse in der Geschichte des Lebens.
Die Autoren schlagen drei Stadien vor: eine erste Periode, in der Moleküle ähnlich wie Nukleinsäuren existierten, später wurden die Genome aus RNA gebildet und als letzter Schritt erschienen die Genome der DNA-Doppelbande.
Einige Belege stützen die Theorie einer auf RNA basierenden Primärwelt. Erstens kann die Proteinsynthese in Abwesenheit von DNA erfolgen, jedoch nicht, wenn RNA fehlt. Darüber hinaus wurden RNA-Moleküle mit katalytischen Eigenschaften entdeckt.
Wie bei der Synthese von Desoxyribonukleotiden (in DNA vorhanden) kommt es immer zur Reduktion von Ribonukleotiden (in RNA vorhanden).
Für die evolutionäre Innovation eines DNA-Moleküls müssen Enzyme vorhanden sein, die DNA-Vorläufer synthetisieren und an der Retrotranskription von RNA beteiligt sind.
Durch die Untersuchung der aktuellen Enzyme kann der Schluss gezogen werden, dass sich diese Proteine mehrmals entwickelt haben und dass der Übergang von RNA zu DNA komplexer ist als bisher angenommen, einschließlich Prozessen des Gentransfers und -verlusts und nicht-orthologer Ersetzungen.
DNA-Sequenzierung
Die DNA-Sequenzierung umfasst die Aufklärung der Sequenz des DNA-Strangs anhand der vier Basen, aus denen er besteht.
Die Kenntnis dieser Reihenfolge ist in den Biowissenschaften von großer Bedeutung. Es kann verwendet werden, um zwischen zwei morphologisch sehr ähnlichen Arten zu unterscheiden, Krankheiten, Pathologien oder Parasiten zu erkennen und sogar eine forensische Anwendbarkeit zu besitzen.
Die Sequenzierung von Sanger wurde in den 1900er Jahren entwickelt und ist die traditionelle Technik, um eine Sequenz zu klären. Trotz seines Alters ist es eine gültige Methode, die von Forschern weit verbreitet ist.
Sangers Methode
Das Verfahren verwendet DNA-Polymerase, ein äußerst zuverlässiges Enzym, das DNA in Zellen repliziert und eine neue DNA-Kette unter Verwendung einer anderen, bereits bestehenden Richtlinie synthetisiert. Das Enzym benötigt einen Primer, um die Synthese zu starten. Der Primer ist ein kleines DNA-Molekül, das zu dem zu sequenzierenden Molekül komplementär ist.
Bei der Reaktion werden Nukleotide zugesetzt, die vom Enzym in den neuen DNA-Strang eingebaut werden sollen.
Zusätzlich zu den "traditionellen" Nukleotiden umfasst das Verfahren eine Reihe von Didesoxynukleotiden für jede der Basen. Sie unterscheiden sich von den Standardnukleotiden in zwei Merkmalen: Sie erlauben der DNA-Polymerase strukturell nicht, mehr Nukleotide an die Tochterkette anzuhängen, und sie haben für jede Base einen anderen Fluoreszenzmarker.
Das Ergebnis ist eine Vielzahl von DNA-Molekülen unterschiedlicher Länge, da die Didesoxynukleotide zufällig eingebaut wurden und den Replikationsprozess in verschiedenen Stadien stoppten.
Diese Vielzahl von Molekülen kann nach ihrer Länge getrennt werden und die Identität der Nukleotide wird mittels der Lichtemission der fluoreszierenden Markierung abgelesen.

Sequenzierung der neuen Generation
Die in den letzten Jahren entwickelten Sequenziertechniken ermöglichen die massive Analyse von Millionen von Proben gleichzeitig.
Zu den herausragendsten Methoden zählen die Pyrosequenzierung, die Sequenzierung durch Synthese, die Sequenzierung durch Ligation und die Sequenzierung der nächsten Generation durch Ion Torrent.